Já faz bastate tempo
O ano é 2026, eu não posto nada no meu blog faz dois anos, e todo mundo ainda está falando sobre IA. Não vou dizer que IA é algo ruim, mas a forma como as coisas estão sendo feitas recentemente não me agradam. Porém, não estou aqui para falar sobre aceleracionismo. Estou aqui para aprender, eu estou precisando estudar esse assunto tem um tempo, e talvez eu esteja ficando para trás por causa disso.
Tem gente dizendo que não escreve mais código, que programar é algo obsoleto. Esse é o tipo de coisa que dá medo de ouvir, faz você repensar sua carreira. Então eu decidi aprender mais sobre o assunto, e vou postar aqui as coisas que eu achar interessantes nessa série chamada TIL (Today I Learned).
Na verdade, são LLMs
IA é meio que um termo de marketing. O que a maioria das pessoas está usando agora se chama LLM (Large Language Model). Chamar isso de IA pode ser enganoso. Ainda não chegamos lá, e talvez nunca vamos chegar usando esse modelo.
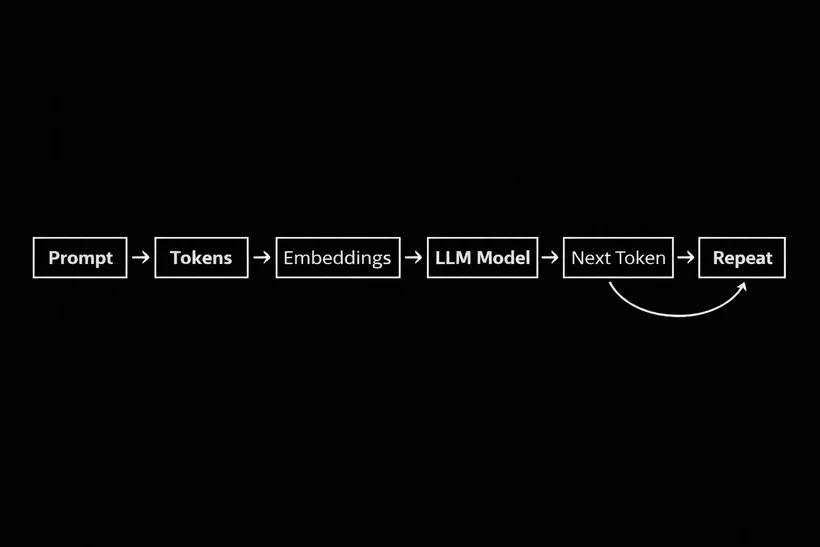
Basicamente, pelo que eu entendi, o LLM se resume a números. Deixe eu explicar: tudo que você digita, o seu prompt, será convertido em um array de tokens. Tokens podem ser palavras completas, partes de uma palavra ou símbolos, e eles também possuem IDs. Imagine que cada ID tenha um vetor associado a ele. Esse vetor pode ter de 4 a 4096 dimensões e representa o significado daquele token de forma numérica, para que o modelo possa trabalhar com ele. Então, quando você digita algo, o LLM basicamente converte tudo em números e tenta adivinhar, com base no treinamento que recebeu, quais palavras têm maior probabilidade de vir como resposta.
A ideia de prever a próxima palavra em uma frase existe faz tempo, mas só recentemente conseguimos o poder computacional e dados suficientes para treinar esses modelos em larga escala.
Quando os LLMs se tornaram super acessíveis para o público com o ChatGPT, as coisas começaram a sair do controle. Porque agora essa coisa complexa e acadêmica tá disponível para todo mundo, e o que realmente tornou isso tão relevante hoje é que desenvolvedores podem fazer aplicações com isso.
IAs agenticas
Então LLMs meio que “pensam”, mas eles não conseguem interagir com as coisas… ainda. Quando perguntamos algo para o ChatGPT, por exemplo, ele simplesmente faz uma requisição enviando nosso prompt como parâmetro no body, o velho e simples método POST. Ele não consegue fazer nada além disso. Apenas lê a requisição, processa no modelo e devolve a resposta.
Mas e se também for enviado uma lista de ações que ele pode executar? Assim ele poderia realizar ações quando necessário, com base no nosso prompt. É aí que entram as tools, e é isso que faz um LLM parecer uma IA.
Com as tools, coding agents como o Claude Code se tornaram possíveis. Quando você pede algo para ele, o sistema envia seu prompt junto com uma lista de funções e descrições de cada uma delas, para que o LLM possa fazer o uso de alguma ferramenta caso necessário. Ferramentas podem fazer qualquer coisa: ler arquivos, editar arquivos, obter a previsão do tempo. Você pode até pedir para o LLM listar as ferramentas disponíveis. Isso abre muitas possibilidades, e basicamente representa onde estamos agora.
Também temos rules, skills e MCPs, mas isso fica para outro post.
Limitações
Bom, se ele consegue “pensar” e executar tarefas, o que sobra para gente? Bom, por enquanto existem limitações. Algumas são físicas, como a enorme quantidade de energia necessária para produzir tudo isso. Mas a principal é algo que ainda não foi falado: contexto.
Todo modelo possui uma janela de contexto, que é a quantidade de tokens que ele consegue lidar sem aumentar muito a chance de alucinação. Quando fazemos um prompt, também enviamos nossas rules, tools, skills e a própria mensagem para o LLM. Tudo isso vira tokens, como já foi dito. Mas toda vez que algo novo é enviado para o LLM, todos os dados anteriores também são enviados novamente, tudo é reprocessado. Imagine ler um arquivo grande, isso pode estourar sua janela de contexto bem rápido. Ter muitas ferramentas também pode diminuir o espaço disponível, por causa da quantidade de tokens que elas adicionam já no começo.
Quando ocorrem alucinações, o modelo gera respostas que parecem corretas, mas na verdade estão erradas. LLMs não “sabem” realmente das coisas. Eles apenas geram texto com base em padrões aprendidos durante o treinamento. Outro ponto importante: LLMs não são determinísticos. O mesmo prompt pode gerar respostas diferentes cada vez que roda.
Por causa de tudo isso, ainda precisamos gerenciá-los. Mesmo com uma janela de contexto grande, ainda é necessário uma direção para fazer as coisas corretamente.
E agora?
Bom, essa é a primeira parte da série, e eu ainda não sei quantas partes ela vai ter. Aprender o básico de como tudo funciona me deixou menos preocupado com tudo que está acontecendo. Provavelmente muitas pessoas já sabiam de tudo isso, mas eu não sabia. Se você também não sabia, você acabou de ter mais contexto sobre o assunto.
Tem muito mais conteúdo para aprender sobre LLMs, logo logo teremos mais posts.