It’s been a long time
It’s 2026, I haven’t posted anything on my blog since the last two years, and everyone is still talking about AI. I’m not saying that AI is bad, but the way things are being pushed is not good in my opinion. But I’m not here to talk about accelerationism. I’m here to learn, and I’ve been delaying studying this topic for a long time, and I may be falling behind because of it.
People are all saying that they don’t write code anymore, that coding is getting obsolete. It’s the kind of stuff that makes you scared, or makes you rethink your career. So I decided to educate myself about this matter, and I’m going to post things that I find interesting here, in this TIL (Today I Learned) series.
Actually, it’s LLM
AI is kind of a marketing word. The thing that most people are using right now is called an LLM (Large Language Model). Calling it AI may be deceiving, it’s not quite there yet, and maybe it will never be if using this model.
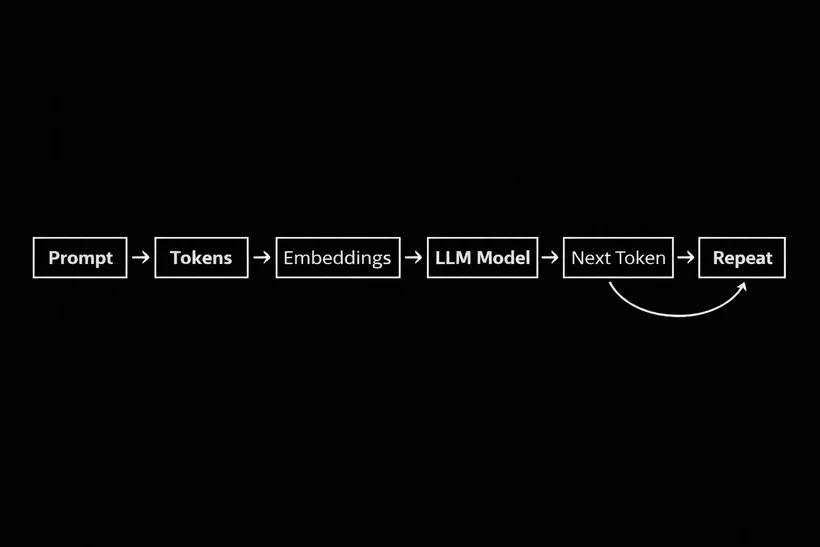
Basically, from my understanding, a LLM is all about numbers. Let me explain, everything that you type, your prompt, will be converted into an array of tokens. Tokens can be full words, parts of words, or symbols, and they also have IDs. Imagine that each ID has a vector attached to it, it can contain 4 to 4096 dimensions, and it represents the meaning of that token in a numeric way so the model can work with it. So when you type something, basically the LLM converts everything into numbers and guesses, based on its training, which words are most likely to come next as an answer.
The idea of predicting the next word in a sentence has existed for decades, but just recently we got the computing power and the data needed to train models like this at a massive scale.
When the LLMs became widely accessible to the public through ChatGPT, things started to get crazy. Because now this complex, academic thing is accessible, and what made it such a big deal today, developers can do stuff with it.
Agentic AIs
So LLMs can kind of “think”, but they can’t interact with stuff… yet. When we ask something to ChatGPT, for example, it simply makes a request sending our prompt as a body parameter, plain old REST POST method there. It can’t do anything more, it just reads the request, processes it in the model and sends the response back.
But what if we also send a list of actions it can make, so it can do stuff for us if necessary, based on our prompt. That’s where the tools come to work, and that’s what makes an LLM feel like an AI.
With tools, coding agents like Claude Code became possible. When you ask something to it, it will send your prompt and a list of functions with descriptions for each one, so the LLM can request to use some tool. Tools can be anything, there are tools to read files, edit files, get the current weather, you can actually ask your LLM to list the available tools. This opens up a lot of stuff to do, and it’s basically where we are now.
We also have rules, and skills, and MCPs, but I may be getting ahead of myself for this post.
Limitations
Well, if it can “think” and execute tasks, we are all doomed, right? Maybe, but right now there are some limitations. Some of them are physical, like the huge amount of energy to produce this. But the main one is something that we haven’t talked about, context.
Every model has a context window, that is the amount of tokens it can handle without having a high chance of hallucinating. When we prompt something, we also send our rules, tools, skills, and the actual message to the LLM. Everything will become tokens as we said, but every time we send something new to the LLM, all the previous data is sent again as well, everything is reprocessed. Imagine reading a large file, it can break your context window pretty quickly. Having a lot of tools can also make it smaller because the amount of preloaded tokens they add.
If hallucinations happen, it will produce answers that sound correct but are actually wrong. LLMs doesn’t really “know” things, it just generates text based on patterns it learned during training. Another major thing, LLMs are not deterministic, the same prompt can generate slightly different answers each time.
Because of all that, we are still needed to manage it, and even with some large context window, it still needs direction to do things right.
Now what?
Well, this is the first part of the series, and I don’t know how many it will be. Learning the basics of how it works made me feel less worried about all that is happening. Probably a lot of people already knew about all that, but I didn’t. If you also didn’t, I’m glad that I gave you more context on this subject.
Stay tuned because there is a lot more to learn about LLMs.